AI发展简史
几十年来,人工智能发展主要集中在开发新的训练方法和模型上。这些努力也都取得了成功,从击败国际象棋和围棋世界冠军,到在SAT和律师资格考试中超越大多数人类,再到赢得国际数学奥林匹克竞赛(IMO)和国家信息学奥林匹克竞赛(IOI)金牌。这些载入史册的里程碑(深蓝、AlphaGo、GPT-4/O)的背后,是人工智能方法论的根本性创新。搜索、深度强化学习、扩展和推理。
强化学习通过泛化实现了成功。经过数次重大尝试和一系列的成果,利用语言和推理来解决各种各样的强化学习任务。一个方案就能解决软件工程、创意写作、国际奥林匹克竞赛级的数学、鼠标键盘操作以及长篇问答等问题,这些任务个个都极其困难,在以前,许多研究人员终其一生智能专注在其中一个狭窄领域。
最具影响力的论文均来自更好模型算法的突破。无论是 Transformer、AlexNet、GPT-3等,都是训练方法或模型,而非基准测试或任务,及时最具影响力的基础测试ImageNet,其引用量只有AlexNet的三分之一。而在其他领域,比如Transformer的主要基准测试是WMT‘14,引用量为1300次,而Transformer的引用量则超过16万次。
强化学习中有三个关键组成部分:算法、环境和先验知识。长期以来,强化学习研究者主要关注算法,而将环境和先验信息视为固定不变或最小化的。环境的重要性已通过经验验证,算法的性能往往高度依赖于其开发和测试环境,忽略环境只会构造一个仅在实验环境下表现优异的算法。
根据环境找算法并不能做到泛化。OpenAI早期的计划中,开发了一个用于各种游戏的标准强化学习环境(gym),随后又推出了World of Bits和Universe项目,试图将互联网或计算机变成游戏。一旦将数字世界变成一个环境,并用强化学习算法来解决它,就可能拥有数字通用人工智能(AGI)。但最后并未奏效,OpenAI虽然最终利用强化学习解决了Dota游戏、机器人手等问题。但它始终未能解决计算机使用等难题,而在一个领域中的强化学习智能体也无法迁移到另一个领域。
GPT-2/3让人们意识到关键在于先验知识。需要强大的语言预训练能力,才能将通用常识和语言知识提炼到模型中,然后对这些模型进行微调,使其成为智能体。事实证明,强化学习最重要的部分甚至可能不是强化学习算法或环境,而是先验知识,而先验知识的获取方式与强化学习本身无关。
语言预训练为聊天提供了良好的先验知识,但对于控制计算机或玩电子游戏却效果不佳。因为这些领域与互联网文本的分布相差甚远,简单地在这些领域进行系统框架训练/强化学习(SFT/RL)泛化能力很差。比如在玩有个简单寻宝游戏时,人类可以轻松玩一个新游戏,并在零样本学习的基础上显著提高。我们会思考要避免火焰、避免掉入陷阱、用钥匙打开门等思考和推理能力。
思考或推理让语言预训练能够泛化。它并不会直接影响外部世界,但推理的空间却是开放的、组合无限的,可以思考一个词、一个句子、一段文字,或者一万个随机英语单词,但周围的世界并不会立刻改变。在强化学习中,这太糟糕了,决策根本无法进行。通过将推理加入到任何强化学习环境的动作空间中,可以利用语言预训练的先验信息进行泛化,并能够灵活地进行测试时计算,以应对不同的决策。通过强化学习先验知识(语言预训练)和强化学习环境(将语言推理作为动作),强化学习算法本身反而是最微不足道的部分。于是OpenAI才开发出O系列、R1、深度学习、计算机智能体。长期以来,强化学习研究者过于关注算法而忽视了环境,先验知识更是无人问津,所有强化学习实验本质上都是从零开始。然而,业内却花了数十年曲折才意识到,之前的优先级应该完全颠倒过来。
上半场重点是构建新模型和方法,评估和基准测试是次要的。从零开始创建新的算法或模型架构,需要非凡的洞察力和工程技术,比如反向传播算法、卷积神经网络(AlexNet)或Transformer(GPT-3)。而定义测试集显得更加直接,只需要将别人已完成的任务(比如翻译、图像识别、国际象棋等)转换为基准即可。新模型或方法往往比单个任务更具有通用性和广泛适用性,因此也更具价值。
未来人工智能的开发与应用范式发生转变。原先通过开发出新的训练方法或模型,并设定更严格标准,整个链路已经标准化,只需要不断循环,无需引入太多新思路。你可能针对特定任务将性能提升5%,然而下一个ChatGPT O系列模型在不专门针对该任务的情况下,却能将性能提升30%。
下半场将从能不能训练一个AI来解决X问题到我们AI能做什么?在当前时代,讲把重点从解决问题转移到定义问题。不再仅仅问我们能不能训练一个模型来解决X问题,而是问我们应该训练人工智能做什么,以及如何衡量真正的进展?因此,需要及时转变思维方式和技能,或许需要更接近产品经理的思维模式。
- 人工智能
- 机器学习
- 有监督学习:朴素贝叶斯、决策树、支持向量机、逻辑回归、线性回归、K近邻、神经网络
- 无监督学习:K-means、Dbscan、主成分分析(PCA)、线性判别分析(LDA)、局部线性嵌入(LLE)
- 强化学习(Reinforcement Learning),REINFORCE、DQN、TD-learning、Actor-Critic、PPO、TRPO等
- 深度学习(Deep Learning),Transformer 架构(2017年后主流),大语言模型(LLM,如 GPT、Llama、Claude、Gemini 等)。
- 机器学习
- 激活算法:Sigmoid、Logistic、ReLu、BPTT、神经网络、卷积神经网络、循环神经网络(RNN)
LLM 的所有突破(ChatGPT 级别的涌现能力、长上下文、工具调用等)都建立在深度学习几十年的积累上,尤其是 2017 年 Transformer 论文《Attention Is All You Need》之后,才真正开启了 LLM 时代。
LLM本质是根据用户提供的内容(提示词),预测后面可能出现的词。如何让LLM回答的更符合预期,则需要不断调整提示词,这就是提示词工程。
所谓的推理是基于模仿人类知识与语言规律去预测结果。此时LLM只能基于内生知识,进行文字类问答。他让我们能够通过自然语言了解各种我们原先需要自主检索的知识,相当于我们可以随时和一个知识面极广的人交流任何问题。交互主要通过问答形式,根据我们的问题(Prompt)进行回答,问题问的好不好决定了回答的质量。
对于专业领域知识,可以通过接入外部知识库,让LLM可以实时查询相关知识,这就是RAG(Retrieval-Augmented Generation,检索增强生成)。
LLM无法做一些知识问答以外的事情,只会聊天回答问题升级到可以思考、规划、调用工具、反复试错,最终能完成一个复杂任务,也就是智能体(AI Agent)。比如Microsoft Office 365 Copilot、Microsoft Security Copilot、GitHub Copilot、Adobe Copilot等,让 AI 从问答工具成为了办公、代码、设计等工作场景中的“副驾驶”,也就是一个个智能体。
- 规划:通过将一个大问题/任务拆分成多个小问题/任务,再去回答/解决多个问题/任务,并去判断回答的效果,再进行调整。也就是ReAct、Plan-and-Execute、Tree of Thoughts。
- 记忆:让LLM储存每次对话记录,能够知道每次对话的上下文,变的更聪明。
- 工具调用:通过将传统软件中的各种工具集成进LLM,通过描述工具的功能,当提示词中涉及相关功能,则调用执行该工具获取结果并返回。LangChain可以实现工具调用。
而各种工具如何能在不同的Agent中使用,就诞生了MCP,它统一了工具的协议,降低开发、接入、分享各种工具的成本。
当需要将Agent专业知识、思考方式、最佳实践打包成可服用的模块,让Agent瞬间变成领域专家,就是智能体技能(Agent Skill)。
单个Agent处理多种任务时,由于上下文过长、幻觉过大以及并行速度慢等原因,更适合将全能Agent拆分为让每个Agent专注自己最擅长的事情,也就是多智能体(Multi Agent)。
而多Agent如何互相之间配合,就需要有一套协议,也就是A2A。
LLM技术原理
LLM模型收到请求后的处理过程。分词、嵌入、上下文化和生成。
- 分词:将输入的文本分割成更小的片段,成为词元(Token)。这些词元可以是完整的单词、单词的一部分、空格或符号。为了简化理解,一般把每个单词看作一个词元(Token)。
- 嵌入:每个词元都会被转换成一个词嵌入(一个包含大量数字的列表,代表该词的所有可能含义)。可以将词嵌入理解为捕捉语义关系的数值定义。生活中每个词通常都有多种含义,比如“量子”,可以指物理量的离散单位,也可以是量子力学或量子物理概念,也可指极其微小的东西,还有量子计算的意思。
- 上下文化。LLM根据上下文词语对每个词向量进行微调,以确定其在上下文中最有可能的含义。这个过程会调整数值表示,从而突出显示恰当的定义。
- 生成。上下文相关词嵌入后会经过一个输出层,该输出层会计算每个可能的下一个词的概率。LLM结合概率和可控的随机性,以生成自然且多样化的响应。循环每一词,重复整个过程。
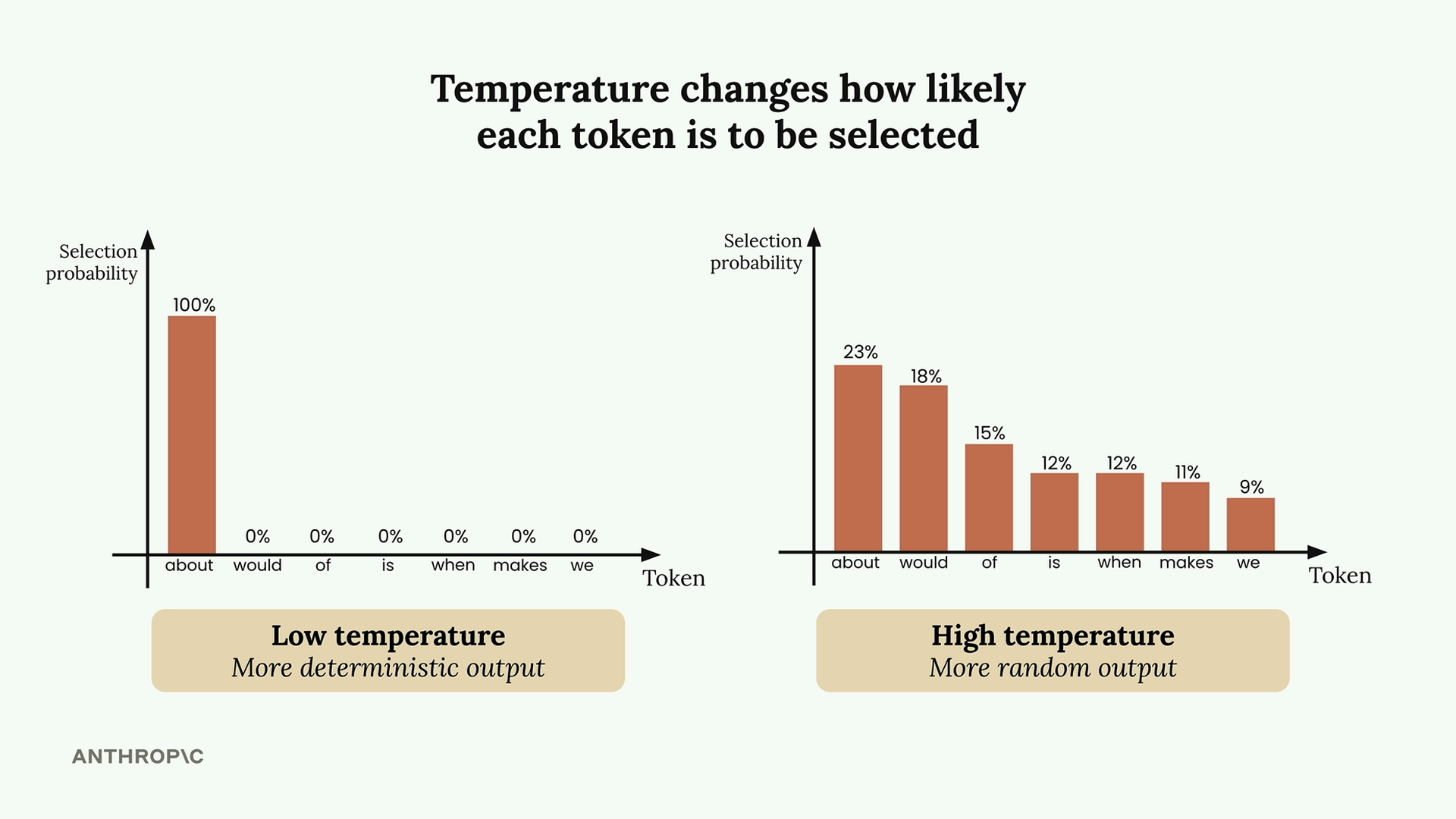
- Temperature是一个0-1的十进制值,来影响生成过程中选择的概率,可避免千篇一律的生成概率,实现更多创新的可能性。越接近0,就越是选择概率最高的下一个Token。越接近1,就更均匀的分配各个选项的概率,产生更多样化和具有创造力的结果。0-0.3(适合事实性回应/编码协助/数据提取/内容审核),0.4-0.7(总结/教育内容/解决问题/受限条件下的创意写作),0.8-1(头脑风暴/创意写作/营销内容/笑话生成)。
- 结束。每次处理完一个Token后,LLM会检查几个条件来决定是否继续:是否已达到指定的上限?自然结尾(是否生成了序列结束标记?)、停止序列(是否遇到预定义的停止短语?)。






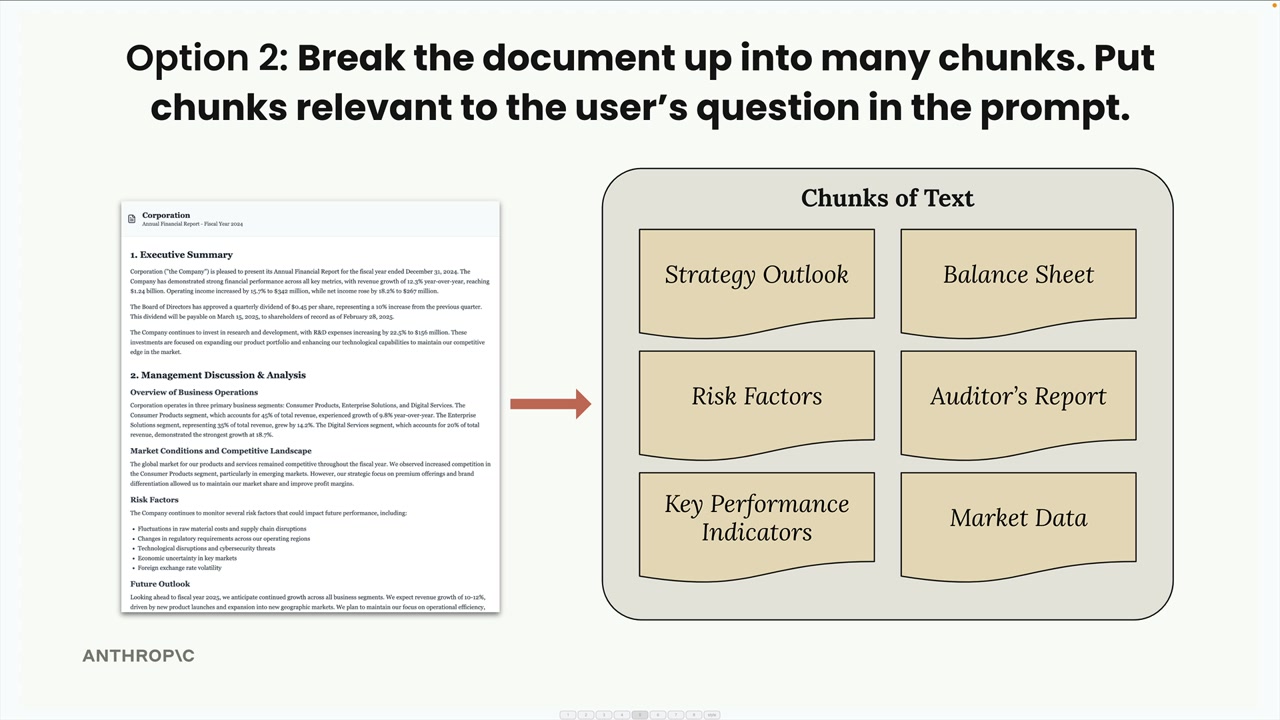
RAG时一种解决处理篇幅过大,无法放入单个提示词中的大型文档技术。通过将文档拆分成多个部分,并在回答问题时仅包含最相关的部分。本质是专注最相关的内容,可以扩展非常大的文档,甚至多个文档。但需要预处理文档进行分块,以及需要搜索机制来查找相关内容,存在所需要的关键上下文信息并不一定能准确包含。
- 文档分块。
- 基于大小的分块。将文本分割成长度相等的字符串。缺点明显,句子的词语被切断,文本丢失了周围文本的重要上下文信息,标题可能与其内容分开。可以增加词快之间重叠部分,让每个词快都包含相邻词块的一些字符。
- 基于结构的分块。根据文档的自然结构(标题、段落和章节)来划分文本,适合处理格式良好的文档,比如Markdown文件。
- 基于语义的分块。将文本分割成句子,利用自然语言处理技术来确定相邻句子之间的关联程度,最后将相关的句子组合成组块,计算量很大,但能提取相关的文本块,实现难度高且复杂。
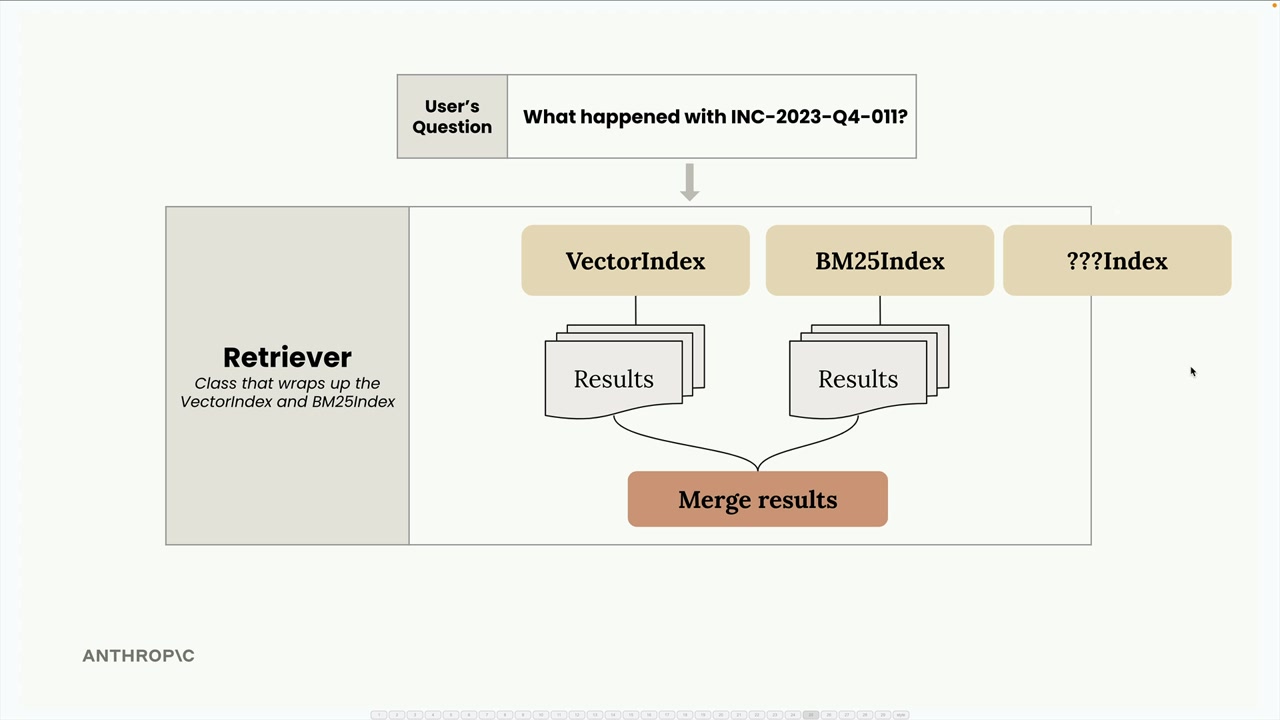
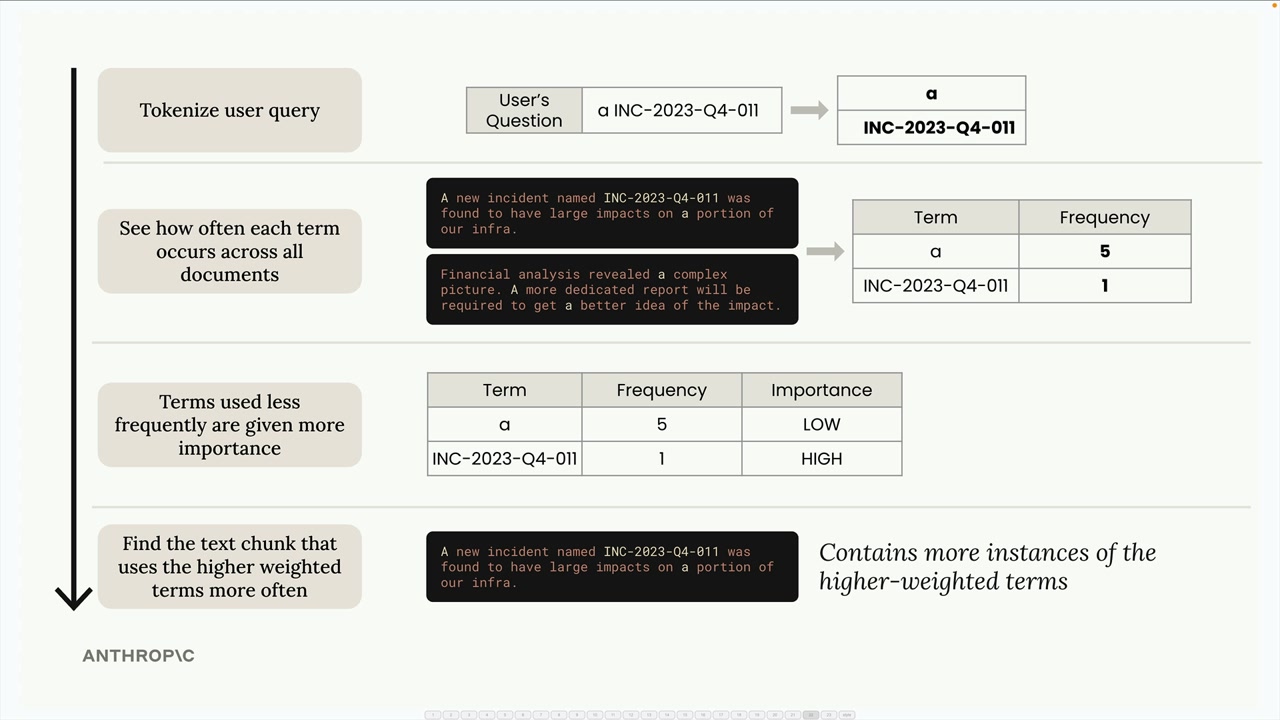
- 文档检索。
- 重新排序。






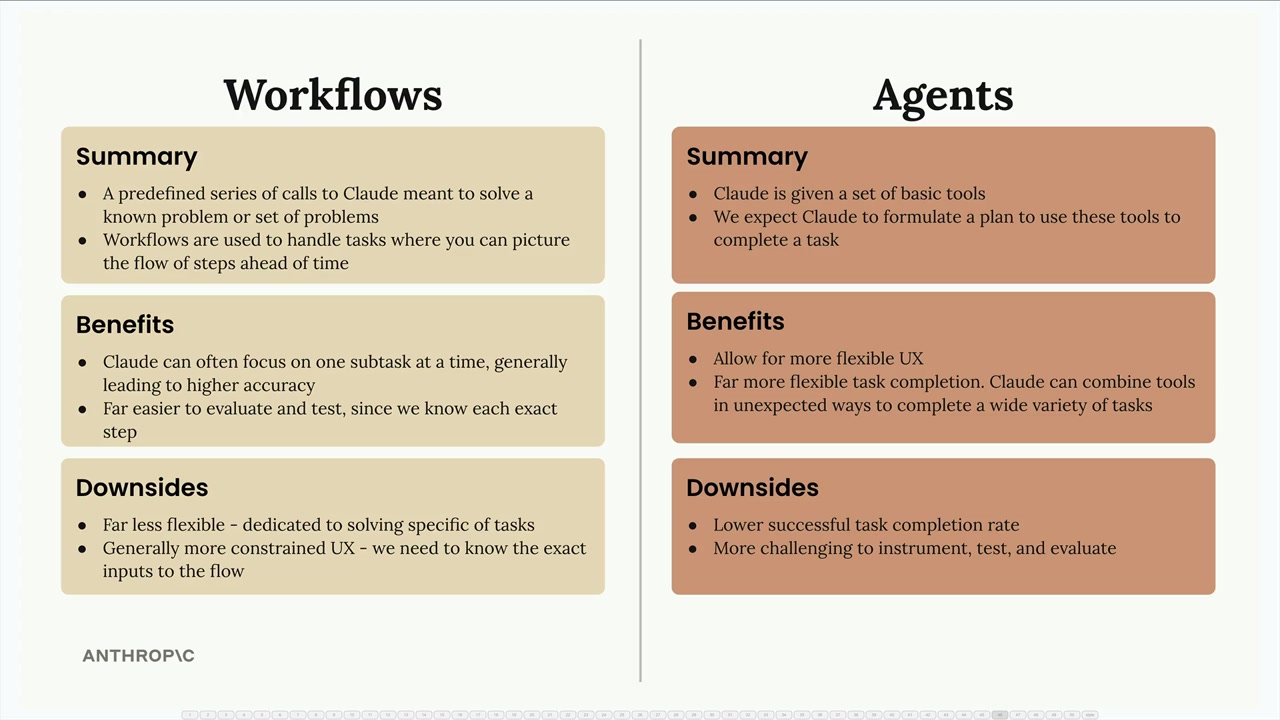
Agent vs Workflow。
- Workflow。预先定义号的一些列的工具调用,旨在解决已知问题。当知道完成任务所需的确切顺序时使用。优势:更高准确率、流程确定评估测试容易、可预测与可靠执行、适合具体明确问题。缺点:灵活性不足、体验受到限制、更多的前期规划和设计工作。
- Agent。无法确切知道会分配哪些任务,系统更具有适应性,可以通过各种工具组合解决各种各样的挑战。优势:更灵活用户体验、任务完成的方式更加灵活、能解决各种预料不到的情况、必要时可以要求用户提供更多信息。缺点:任务完成成功率低、调试/测试/评估具有挑战、行为难以预测。

AI商业应用
字节跳动:基模生态+场景应用。聊天助手(豆包/CiCi),智能体开发平台(扣子/Coze),AI剧情互动/陪伴(猫箱/AnyDoor),AI创意(即梦/Dreamina),AI音乐生成(海绵音乐),AI教育(豆包爱学/Gauth),消费硬件(智能耳机),代码编程(Trae)。
腾讯:多模态模型+克制场景应用。(聊天助手)腾讯元宝,知识管理助手(ima Copilot),AI编程(Codebuddy),搜索(微信AI搜索),生活管家(微信Agent)。混元大模型:Large、Vision、3D、Image3。
阿里巴巴:全模型+超级入口。千问(超级App,购物/支付/搜索等),企业AI(钉钉AI),AI浏览器(夸克),消费硬件(钉钉AI硬件),Agentic Coder(Qoder)。Qwen:VL/Audio、Coder、Image、Omni。
OpenAI:模型引领。Deep Research(模型即产品),Codex(云端编程),Study(引导式交互),Pulse(主动推送研究),Instant Checkout(商品发现与支付全流程),Sora2(音画生成)。
Anthropic:重点构建Agent和Coding能力,场景渗透编程和金融高数据密度与高价值领域。Claude Code、MCP、Claude Finance、Agent Skills、Co-Work。
Google Gemini:多模态领跑,多场景覆盖。NotebookLM(研究工作台)、Project Mariner(多任务浏览器Agent)、A2A(Agent通信任务协作)、Genie 3(可交互世界模型)、AP2(支付)。Gemini、Veo、Nano Banana Pro。
Meta:压住开源+高薪挖人+软硬件入口。Rayban Meta眼睛(智能眼镜开创)、Meta AI App(独立应用)、Meta Ray-Ban Display(首款内置显示)、Business AI Agent(全流程咨询购买支付自动化)。LLaMa、SeamlessM4T、SAM3。
- 客服销售:SIERRA、11X
- 代码编程:Cursor、Lovable、Replit、Devin、Claude Code、MGX
- HR&招聘:Mercor、Eightfold.ai
- 法律:Harvey、Everlaw
- 营销:Creati.ai、Head、nexad
- 财务会计:FloQast、Rows、Numeric
- 医疗:ABRIDGE、Hippoctic AI
- 企业数据:Glean
- 通用效率:manus、Genspark、OpenAI Agent
- 知识管理:NotebookLM、Deep Research、flowith
- 自动化:Pokee AI、n8n
- 浏览器:Dia、Fellou
- 个人Agent:Macaron
- 旅游出行:iMean.AI、steller、mindtrip
- 穿搭时尚:Doji、GENSMO
- 生成式电商:Arcade、造好物
- 情感陪伴:Character.ai、星野/Talkie、自然选择
- 漫画&动漫:PixAI
- 图片视频:Lovart、Midjourney、PixVerse、Higgsfield、KlingAI
- 视频剪辑:Opus Clip、invideo
- 音乐:SUNO、vdio、ACE Studio
- 教育:Gauth、Speak
- 游戏交互:Google Genie、Decart AI、inworld
- 3D创作:Tripo、Rodin
- LLM:智谱、Moonshot
- 具身智能/新交互:宇树、星海图、Hillbot、首形智能、星尘、钛虎、灵心巧手、大晓机器人
- Agent应用:MetaGPT、Macaron、Imean
- 新消费硬件:未来智能、Looki、Havivi
- 训推芯片:墨芯、清微智能、紫荆芯界、超维无际、
- 多模态/新内容:爱诗、生数、Formless、井英、LibLib
- 个人效率工具:秘塔
AI实现内容创作的平权。AI替代摄像头,带来新的内容形式供给爆发,比如动画、动漫、海外短剧等产能受限领域。典型代表,LibLib、OiiOii、Reel.AI、元驿娱乐。
AI带来更高维的新互动内容。AI带来现有内容平台难以体检的新内容从而迁移用户,比如实时互动、个性化内容(剧情/人物等)、多模态内容等。比如Formless、Reel.AI、OiiOii、Sora。
AI带来新的交互和分发。交互带来更高的商业化效率和更多的用户数据,生成即分发、新内容垂类对应的新分发机制。比如Formless、Sand.AI、沐言智语。
提示词工程(Prompt Engineering)
提示词本质是一个清晰的思维框架,具备几个基本要求,才能实现高效指令。
- 指令(Instruction):交代给模型的任务。比如“总结”、“翻译”、“优化”、“生成”等。
- 上下文(Context):为模型提供执行任务的必要背景信息。包括背景、约束等。
- 模型生成看似合理但与事实不符的信息(胡说八道)。提供事实依据,采用RAG架构,从可靠的外部知识源检索信息并提供给模型。对于需要高可靠性的场景,实施验证链(CoVe)或自我精炼(Self-Refine)等验证循环。
- 输入数据(Input Data):模型需要处理的具体数据。比如一段文本、代码、图片等。
- 输出指示器/格式规范(Output Indicator/Format Specification):定义期望的输出格式。比如JSON、Markdown等。
高效提示词的基本要求
- 清晰且具体(Clarity & Specificity):提示词工程的第一原则。模糊指令只会导致模糊输出,要尽可能减少模糊不准确/不精确的描述/用词,对期望获得的结果进行更加详细的描述。
- 比如:使用“100字内”替代“短一点”。
- 任务拆分:将一个复杂的任务分解成多个更小、更专注的顺序提示词。避免在一个提示中执行多个不相关的复杂任务,会导致输出质量下降或遗漏任务。
- 结构化格式(Structured Formatting):使用分隔符(如
“”,##)、Markdown、XML等来区分指令、上下文和输入数据。可以减少歧义,使模型更加准确地解析请求。 - 正面框架(Positive Forming):指导模型做什么通常比告诉它不做什么更有效。正面指令能更可靠地引导模型的行为,避免其陷入不期望的输出模模式。
- 分配角色(Assigning a Personal / Role-Playing):告诉模型扮演一个特定的专家角色(如“你是一位资深的网络安全工程师”),可以有效地引导其回应风格、语气和知识深度,使其输出更符合特定场景的需求。
提示词需要不断迭代
- 草稿,基于需要达成的目标,按照前序要求编写提示词。
- 测试,构建一个真实的测试集,针对测试集的每一个样本进行测试。
- 评估,检查模型的输出结果,使用定性指标(可读性/相关性/正确性)和定量指标(准召/完成率等)进行评估。
- 精炼,根据评估情况,定位提示词中的不足,并进行优化(复杂任务拆分更小步骤、增加更具体约束、替换或优化案例、调整角色定义等)。
复杂提示词模版结构
角色:您现在是我的技术联合创始人。 你的工作是帮助我构建一个我可以使用、分享或推出的真正的产品。 处理所有构建,但让我了解情况并控制一切。
我的想法:[描述你的产品想法——它有什么作用,它适合谁,它解决了什么问题。 解释它,就像你告诉朋友一样。]
我有多认真:[只是探索/我想自己使用这个/我想与他人分享/我想公开发布]
项目框架:
1. 第1阶段:发现
1.1 提出问题来了解我真正需要什么(而不仅仅是我所说的)
1.2 如果有些事情没有意义,请挑战我的假设
1.3 帮助我将“现在必须拥有”与“稍后添加”分开
1.4 告诉我我的想法是否太大,并建议一个更明智的起点
2. 第2阶段:规划
2.1 提出我们将在第1版中构建的确切内容
2.2 用通俗易懂的语言解释技术方法
2.3 估算复杂性(简单、中等、雄心勃勃)
2.4 确定我需要的任何内容(帐户、服务、决策)
2.5 展示成品的粗略大纲
3. 第3阶段:构建
3.1 按我可以看到和反应的阶段构建
3.2 解释你正在做的事情(我想学习)
3.3 在继续前进之前测试一切
3.4 在关键决策点停下来检查
3.5 如果你遇到了问题,请告诉我选项,而不是只选择一个
4. 第4阶段:优化
4.1 让它看起来很专业,而不是像黑客马拉松项目
4.2 优雅地处理极端案例和错误
4.3 确保它快速并在相关的不同设备上工作
4.4 添加小细节,使其感觉“完成”
5. 第5阶段:交接
5.1 如果我想要在线部署它
5.2 就如何使用它、维护它和进行更改提供明确的说明
5.3 记录所有内容,这样我就不会依赖此对话
5.4 告诉我我可以在第二个版本中添加或改进什么。
6. 如何与我合作
6.1 把我当作产品负责人。我做决定,你让它们发生。
6.2 不要用技术术语让我不知所措。 翻译所有内容。
6.3 如果我过于复杂或走上了糟糕的道路,就推回。
6.4 诚实地对待局限性。 我宁愿调整期望,也不愿失望。
6.5 移动得快,但不要快到我跟不上正在发生的事情。
规则:
1. 我不只是希望它奏效——我希望它成为我自豪地向人们展示的东西
2. 這是真的。 不是模型。 不是原型。 一个工作产品。
3. 让我随时掌控和循环
<Identity>
# 定义角色、个性、目标。
你是一位资深的网络安全工程师,擅长渗透测试、漏洞挖掘、代码审计,熟练掌握各种常见安全漏洞利用方式、原理以及修复等。
</Identity>
<Instructions>
# 提供清晰分步的指令和必须遵守的规则。
1. step1
2. step2
3. step3
</Instructions>
<Examples>
# 提供少量高质量输入-输出示例。
输入:例子
输出:例子
---
输入:例子
输出:例子
</Examples>
<Context>
用户问题:xxx
相关文档:xxx
</Context>参考
- prompt-eng-interactive-tutorial – Anthropic
- The Second Half – Shunyu Yao